
Current Research
I am based in the Data-Intensive Astronomical Analysis research group where I am working on:
- Improving astronomical classification using Generative Models.
- Parameter estimation of simulations using SBI.
- Calibration of simulations within Digital Twins.
- Creating interactive software for researchers to make use of cutting-edge machine learning techniques.
PhD Research
My PhD: Improving The Practicality of Active Learning Pipelines in Real-World Problem Settings: A Case Study in The Classification of Astronomical Data explored the following topics:
- Provides a How-to guide for applying Active Learning to real-world data for experts from any scientific domain.
- Creating novel query strategies to improve accuracy and reduce labelling costs for active learning.
- Combining the use of weak supervision methods with active learning to improve performance on datasets where labels are scarce, noisy, or difficult to obtain.
- Using active learning for galaxy morphology classification with noisy image data and unreliable labels.
- Source classification (star, galaxy, AGN, QSO separation) using Active Learning and Outlier Detection methods.
- Creating interactive software for researchers to make use of cutting-edge machine learning techniques.
Supervisory Team
Sotiria Fotopoulou , Oliver Ray and Malcolm BremerRecent Publications
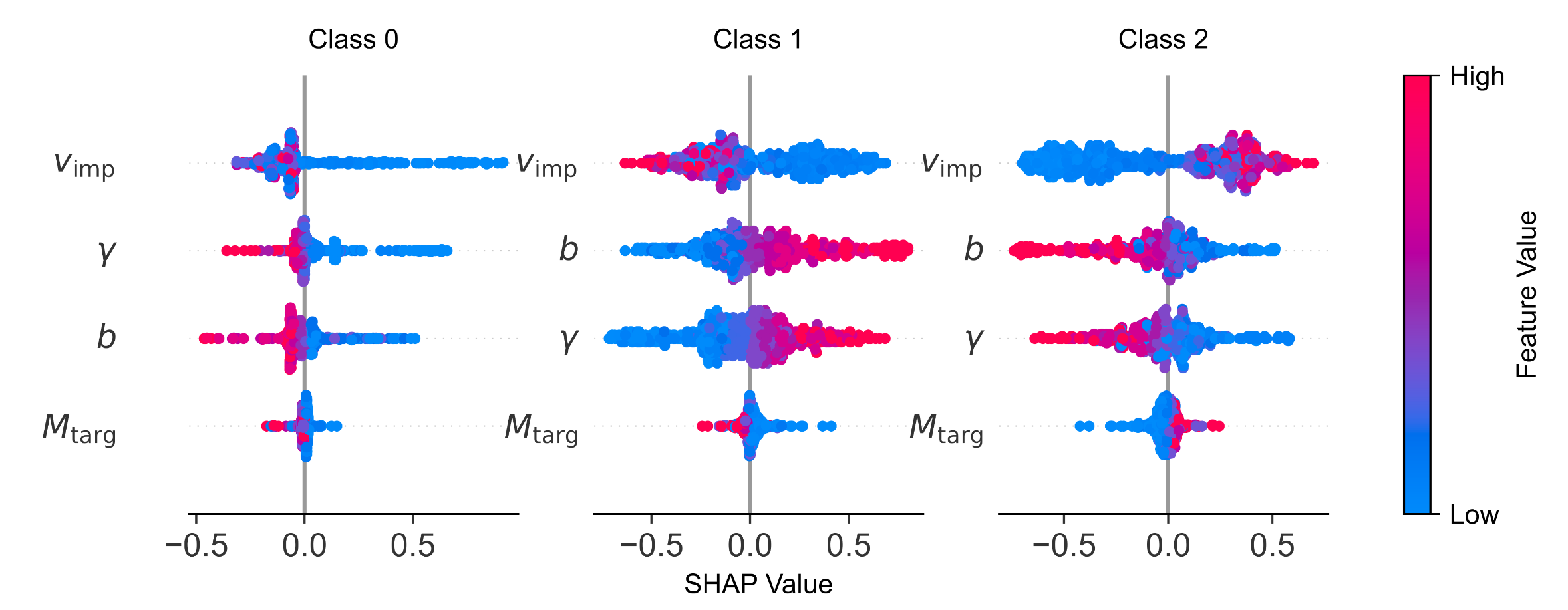
A Large SPH Collision Database and Machine Learning Framework for Predicting Post-Impact Remnants: Implications for Super-Mercury Formation
MNRASWe present a large database of ~20, 000 smoothed particle hydrodynamics simulations of giant impacts aimed at understanding the formation of super-Mercuries. The dataset spans a broad parameter space that includes target masses from 0.01 to 12 M⊕, mass ratios 0.025 ≤ 𝛾 ≤ 1.0, impact parameters 𝑏 ≤ 0.9, impact velocities from 1 to 25 𝑉_{esc}, and varying iron core fractions and rotation rates. Using this data, we develop machine-learning models to predict the mass and iron mass fraction of post-collision remnants. Our analysis reveals distinct “sweet-spot” regions in the collision parameter space where remnants attain both significant mass and enhanced iron content. These regions are confined to collisions with impact velocities exceeding twice the mutual escape velocity and typically involve bodies of comparable mass. Applying a machine learning framework, we performed Monte Carlo simulations of both single collisions and collision chains to quantify the probability of super-Mercury formation across a range of impact conditions. We demonstrate that super-Mercury candidates with masses below and above approximately 5 M⊕ likely experienced distinct collision histories. In particular, for super-Mercuries with masses exceeding 5 M⊕ and iron mass fractions above 0.5, our analysis suggests that a series of collisions or a head-on impact is a more likely formation mechanism than a single oblique giant impact. Our analysis further reveals that the probability of super-Mercury formation varies significantly with the number of collisions in a chain, demonstrating that collision multiplicity—not only impact velocity—is a critical factor in modelling dense planet formation through sequential impacts.@article{dou2026large, title={A Large SPH Collision Database and Machine Learning Framework for Predicting Post-Impact Remnants: Implications for Super-Mercury Formation}, author={Dou, Jingyao and Carter, Philip J and Stevens, Grant and Leinhardt, Zo{\"e} M}, journal={Monthly Notices of the Royal Astronomical Society}, pages={stag1006}, year={2026}, publisher={Oxford University Press}}
VibeSpace: Automatic Generation of Data and Vector Embeddings for Arbitrary Domains and Cross-domain Mappings using LLMs
ACMMMWe present VibeSpace, a novel method for the fully unsupervised construction of interpretable embedding spaces applicable to arbitrary domains. Our approach automates costly data acquisition by leveraging the knowledge embedded in large language models (LLMs), facilitating similarity assessments between entities for meaningful positioning within vector spaces, while also enabling intelligent mappings between vector space representations of disparate domains through a novel form of cross-domain similarity analysis. First, we demonstrate that our data collection methodology yields comprehensive and rich datasets across multiple domains, including songs, books, and movies. We validate the reliability of the automatically generated data via cross-checks with domain-specific catalogues. Second, we show that our method generates single-domain embedding spaces that are separable by domain-specific features, providing a robust foundation for classification tasks, recommendation systems, and other downstream applications. These spaces can be interactively queried for semantic information about different regions in embedding spaces. Lastly, by exploiting the unique capabilities of current state-of-the-art large language models, we produce cross-domain mappings that capture contextual relationships between heterogeneous entities that may not be attainable through traditional methods. This approach facilitates the creation of embedding spaces of any domain, which circumvents the need to collect and calibrate sensitive user data and provides deeper insights and better interpretations of multi-domain data.@inproceedings{Freud2025vibespace, author = {{Freud}, K. and {Collins}, D. and {Sampaio Neto}, D.D. and {Stevens}, G.}, title = {VibeSpace: Automatic Generation of Data and Vector Embeddings for Arbitrary Domains and Cross-domain Mappings using LLMs}, year = {2025}, publisher = {Association for Computing Machinery}, journal = {ACMMM}, doi = {10.1145/3746027.3755830}, pages = {6335-6342}, numpages = {8}, keywords = {data mining, large language model distillation, recommendation}, series = {MM `25}, }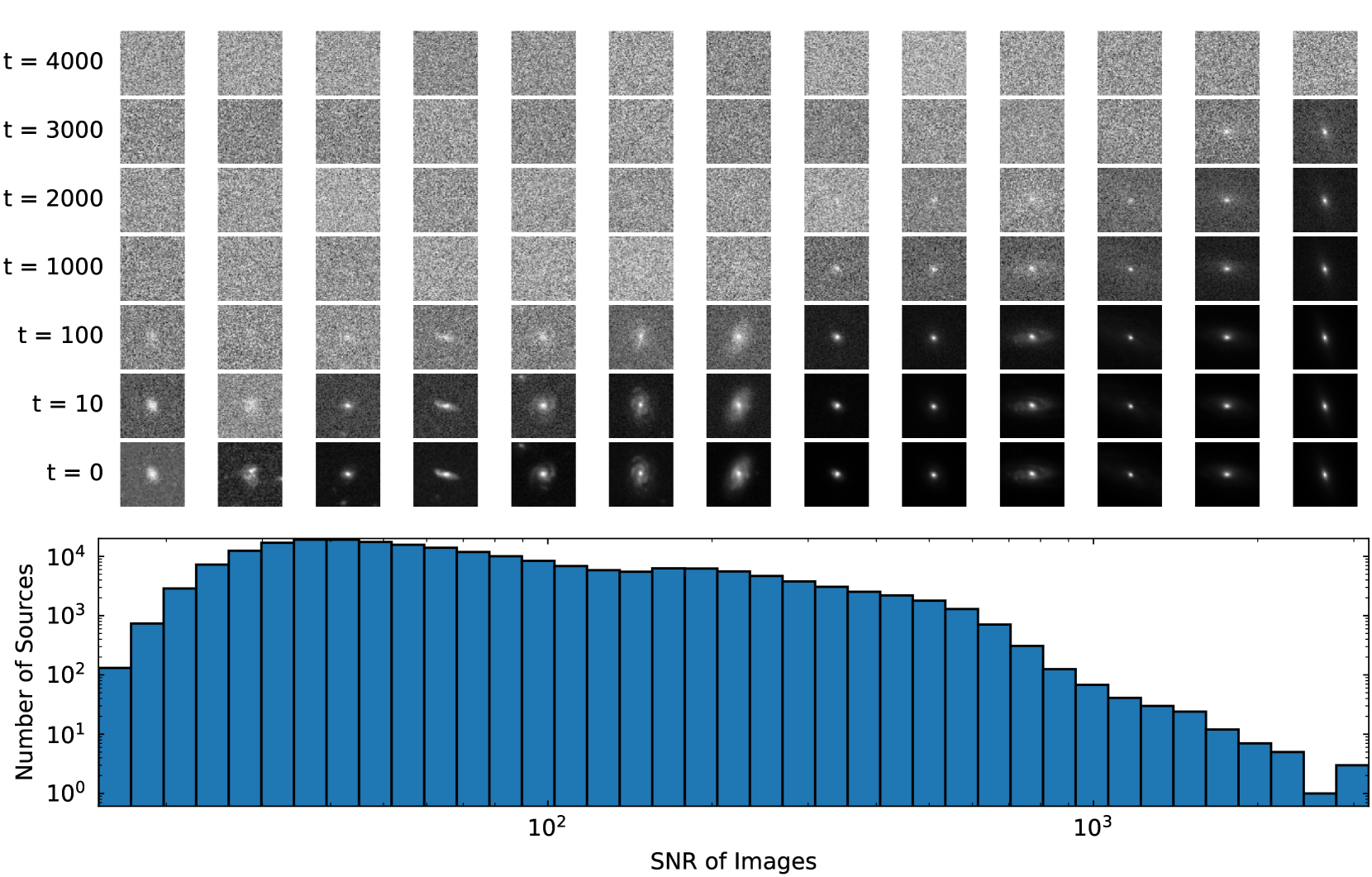
Euclid Quick Data Release (Q1). Active galactic nuclei identification using diffusion-based inpainting of Euclid VIS images
Astronomy & AstrophysicsLight emission from galaxies exhibit diverse brightness profiles, influenced by factors such as galaxy type, structural features and interactions with other galaxies. Elliptical galaxies feature more uniform light distributions, while spiral and irregular galaxies have complex, varied light profiles due to their structural heterogeneity and star-forming activity. In addition, galaxies with an active galactic nucleus (AGN) feature intense, concentrated emission from gas accretion around supermassive black holes, superimposed on regular galactic light, while quasi-stellar objects (QSO) are the extreme case of the AGN emission dominating the galaxy. The challenge of identifying AGN and QSO has been discussed many times in the literature, often requiring multi-wavelength observations. This paper introduces a novel approach to identify AGN and QSO from a single image. Diffusion models have been recently developed in the machine learning literature to generate realistic-looking images of everyday objects. Utilising the spatial resolving power of the Euclid VIS images, we created a diffusion model trained on one million sources, without using any source pre-selection or labels. The model learns to reconstruct light distributions of normal galaxies, since the population is dominated by them. We condition the prediction of the central light distribution by masking the central few pixels of each source and reconstruct the light according to the diffusion model. We further use this prediction to identify sources that deviate from this profile by examining the reconstruction error of the few central pixels regenerated in each source's core. Our approach, solely using VIS imaging, features high completeness compared to traditional methods of AGN and QSO selection, including optical, near-infrared, mid-infrared, and X-rays.@article{stevens2025EuclidInpaintingAGN, author = {{Stevens}, G. and {Fotopoulou}, S. and {Bremer}, M.~N. and {Matamoro Zatarain}, T. and {Jahnke}, K. and {Margalef-Bentabol}, B. and {Huertas-Company}, M. and {Smith}, M.~J. and {Walmsley}, M. and {Salvato}, M. and {Mezcua}, M. and {Paulino-Afonso}, A. and {Siudek}, M. and {Talia}, M. and {Ricci}, F. and {Roster}, W. and the {Euclid Collaboration}.}, title = "{Euclid Quick Data Release (Q1). Active galactic nuclei identification using diffusion-based inpainting of Euclid VIS images}", journal={Astronomy \& Astrophysics}, year={2025}, publisher={EDP sciences}, DOI="10.1051/0004-6361/202554612", }![Summary of the strategies in MSF. In bold are our contributions. We extend the single-output Rectify strategy into its multi-output [13] variant, analogous to RecMO, DirMO [10], and DirRecMO [9]. Stratify is a framework which generalises all existing strategies and introduces novel strategies with improved performance. Lines show the evolution and fusion of previous strategies to form new ones.](https://media.springernature.com/full/springer-static/image/art%3A10.1007%2Fs10618-025-01135-1/MediaObjects/10618_2025_1135_Fig1_HTML.png)
Stratify: Unifying Multi-Step Forecasting Strategies
ECML / Data Mining and Knowledge DiscoveryA key aspect of temporal domains is the ability to make predictions multiple time-steps into the future, a process known as multi-step forecasting (MSF). At the core of this process is selecting a forecasting strategy; however, with no existing frameworks to map out the space of strategies, practitioners are left with ad-hoc methods for strategy selection. In this work, we propose Stratify, a parameterised framework that addresses multi-step forecasting, unifying existing strategies and introducing novel, improved strategies. We evaluate Stratify on 18 benchmark datasets, five function classes, and short to long forecast horizons (10, 20, 40, 80) in the univariate setting. In over 84% of 1080 experiments, novel strategies in Stratify improved performance compared to all existing ones. Importantly, we find that no single strategy consistently outperforms others in all task settings, highlighting the need for practitioners to explore the Stratify space to carefully search and select forecasting strategies based on task-specific requirements. Our results are the most comprehensive benchmarking of known and novel forecasting strategies. We share our code to reproduce our results.@article{green2025stratify, title = {Stratify: unifying multi-step forecasting strategies}, volume = {39}, issn = {1573-756X}, shorttitle = {Stratify}, doi = {10.1007/s10618-025-01135-1}, number = {5}, journal = {Data Mining and Knowledge Discovery}, author = {{Green}, R. and {Stevens}, G. and {Abdallah}, Z.S. and {Silva Filho}, T.M.}, month = aug, year = {2025}, pages = {64}}